Move fast, without sacrificing quality.
Collaboration in the age of agentic engineering.
Collaboration in the age of agentic engineering.
Four pillars. Compounding gains.
Produce artifacts to serve as a shared truth everyone can build on.
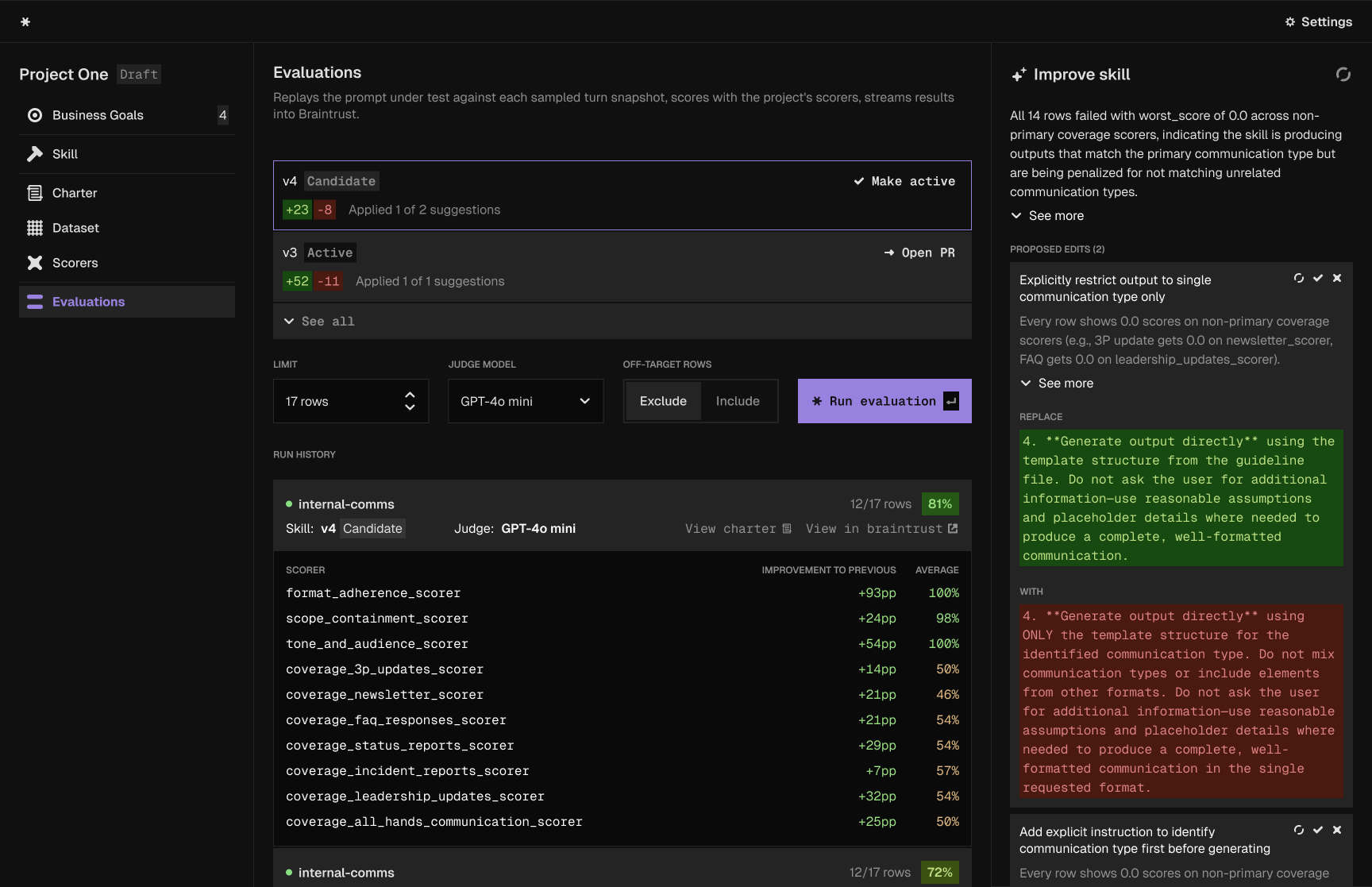
Dataset, scorers, and more →Product owns goals and the spec, engineers focus on runtime and architecture.
Prompt versioning and integrations →An ideal flow
Define goals, capture user stories, set acceptance criteria.
Know what to build and how it'll be graded.
Build the agent scaffolding, plug in the externally versioned skill, hook up tools and observability.
See what works in production and what doesn't.
Review and label new production data, draw consequences, prioritize by impact.
From specs to datasets.
Build a skill from your business goals, or check how well an existing skill serves your purposes.
Synthesize a dataset that can be used directly to measure against to check quality.
Make sure you grade your results according to what is important for your business.
Know where you're headed, understand where you're at.
Measure everything you need and nothing you don't.
Quantify your goals and track your progress against them.
Compare options, make informed tradeoffs.
Distribute responsibilities, enhance collaboration.
Define what good output looks like through natural language. No Python, no judge harness — anyone on the team can author rigorous evals.
Product gets a direct, versioned handle on the prompt. Experiment, tweak, roll back without touching the codebase or breaking trust.
Try a new model and see the impact yourself. Run the eval, compare the scores, ship the swap without engineering tickets.
Let everyone do what they are best at.
Product writes the wishes; engineering gets labeled examples back. The same document that defines the feature also tests it.
Your prompt is the contract for what the feature does. Treat it like a spec: versioned, reviewed, and measurably correct.